Use regular expressions in chatbots
Regular expressions are patterns that you can use when the preset validation methods are insufficient to compare a value received from a subscriber with a template value.
For example, you can use regular expressions to check a phrase for keywords and word count, the presence of spaces and other characters, as well as to enter numbers within a certain value range or check for a link to a social media account.
Regular expression syntax
You can compose a regular expression from regular characters, such as /abc/, or combine regular and special characters, such as /ab*c/.
In the tables below, you can see the basic symbols that are used when composing a regular expression.
Special Symbols
\ |
Shielding Character. Indicates that the following character is a literal character and not a meta-character. For example, \* corresponds to an asterisk as a literal character, not a repetition quantifier |
\n |
New Line. Used to search for line feeds. For example, /\n/ corresponds to a line break in the string
"Work hard. Dream big." |
\t |
Tab. Used to search for the horizontal tab character in strings (ASCII character 9). |
\v |
Vertical tab. Corresponds to any vertical space character. |
\f |
New page. Corresponds to ASCII character 12. |
Anchors
^ |
The beginning of the string. For example, /^B/ does not correspond to "B" in "a B,” but it does in "B a.” |
$ |
End of line. For example, /k$/ does not match the "k" in "walker", but it does match the "walk" string. |
\b |
Word boundary. For example, /\bpump/ corresponds to "pump" in "pumpkin." |
Symbol classes
\s |
Space. For example, /\s/ corresponds to the first space character in the string "that sounds amazing." If the global search flag g is used, /\s/g corresponds to two space characters in the string "that sounds amazing." |
\d |
Digit. Equals the first digit in the line. Equivalent to /[0-9]/. For example, /\d/ corresponds to "2," but does not correspond to "B" in the string "B2 is the suite number." |
\D |
Not a number. Equals the first letter in the string. Equivalent to /[^0-9]/. For example, /\D/ corresponds to "B," but does not correspond to "2" in the string "B2 is the suite number." |
\w |
Word. Corresponds to any first alphanumeric character, including the underscore. Equivalent to /[A-Za-z0-9_]/. For example, /\w/ corresponds to "b" in "bench" and "3" in "$3.52". |
\W |
Not a word. Corresponds to any first non-digit-letter character. Equivalent to the expression /[^A-Za-z0-9_]/.
For example, |
Quantifiers
* |
0 or greater. Corresponds to the preceding character repeated 0 or more times. Equivalent to the expression /{0,}/. For example, /les*/ corresponds to "less" in "Endless love" and "le" in "let it be." |
+ |
1 or greater. Corresponds to the previous character repeated 1 or more times. Equivalent to the expression /{1,}/.
For example, |
? |
0 or 1. Corresponds to the previous character repeated 0 or 1 times. Equivalent to the expression /{0,1}/. For example, /colou?r/ corresponds to both "color" and "colour," or /mo?ustache/ corresponds to both "moustache" and "mustache." |
{n} |
Exactly N times. For example, /a{2}/ does not correspond to "a" in the string "sugar," but it does correspond to both instances of "a" in the string "sugaar" and the first two "a" in the string "sugaaar." |
{n,m} |
Minimum N and maximum M times. For example, /a{1,3}/ corresponds to nothing in the string "sugr," but corresponds to the character "a" in the string "sugar," two instances of "a" in the string "sugaar," and the first three instances of "a" in the string "sugaaaaaaaar." |
Ranges
. |
Any character other than a line break (/\n/). For example, /.e/ corresponds to "ke" in the string "Take care! If the global search flag g is used, the expression /.e/g corresponds to "ke" and "re" in the string "Take care! |
(a|b) |
a or b. For example, /(green|red)/ corresponds to "green" in "green or red apple?" and /(red|green)/ corresponds to "red" in "green or red apple?". |
(...) |
Group of characters. For example, /(...e)/ corresponds to "Have" in the string "Have a nice day! If the global search flag g is used, the expression /(...e)/g corresponds to "Have" and "nice" in the string "Have a nice day! |
[abc] |
a, or b, or c. For example, /[abcd]/ corresponds to the character "b" in the string "basket". If the global search flag g is used, the expression /[abcd]/g corresponds to the characters "b" and "a" in the string "basket." |
[a-q] |
The letter between a and q in lower case. For example, /[e-m]/ corresponds to the character "k" in the string "basket". If the global search flag g is used, the expression /[e-m]/g corresponds to the characters "k" and "e" in the string "basket." |
[A-Q] |
A letter between A and Q in upper case. For example, /[E-M]/ corresponds to the character "K" in the string "BASKET". If the global search flag g is used, the expression /[E-M]/g corresponds to the characters "K" and "E" in the string "BASKET." |
[^abc] |
Not a, b, or c. For example, /[^abcd]/ corresponds to the character "s" in the string "basket". If you use the global search flag g, the expression /[^abcd]/g matches the characters "s," "k," "e," and "t" in the string "basket." |
[^a-q] |
Any lowercase letter that is not in the range a to q. For example, /^[e-m]/ corresponds to the character "b" in the string "basket." If you use the global search flag g, then /^[e-m]/g matches the characters "b", "a", "s" and "t" in the string "basket." |
[0-9] |
A digit between 0 and 9. For example, /[1-5]/ corresponds to the number "2" in the string "B255 is the suite number." If the global search flag g is used, the expression /[1-5]/g corresponds to the digits "2," "5," and "5" in the string "B255 is the suite number." |
Flags
Flags are specified after the regular expression. The order of the flags does not matter.
g |
Global search. For example, /m/g corresponds to both instances of "m" in the string "moments." Without the g flag, the pattern /m/ corresponds to the first "m" in the "moments" string. |
i |
A region-independent search. For example, /m/i matches the "M" character in the "Moments" string. Without the i flag, the /m/i pattern does not match the "M" character in the "Moments" string. |
m |
Multi-line text. For example, /^\D/gm corresponds to the characters "W" and "D" in the following lines.
"Work hard. Dream big." Explanation: |
s |
Read the text as a single line. The text is treated as a single line, in which case the metacharacter "." corresponds to any single character, including the newline character.
Explanation: If a regular expression has a period (.) with the flag |
Metacharacters
Meta-characters are characters that are not letters or numbers but have a specific role in the syntax of a regular expression. For example, * is a repetition quantifier.
To use a meta-character for a different purpose, it needs to be shieldescaped. For example, to make the * symbol no longer be a repetition quantifier but an asterisk symbol, you need to use shielding.
Shielding is done with the \ backslash character. For example, \. , \/, \* and so on.
See the table below for the characters that need to be shieldedescaped.
| ^ | [ | . | $ | { | * | ( |
| \ | + | ) | | | ? | < | > |
To learn more about regular expression syntax, see the table at exlab.net.
How to use regular expressions in the SendPulse chatbot builder
Drag and drop the Message element item from the left pane of the chatbot builder. Activate the Wait for subscriber's reply option. Select the Regular expression as validation.
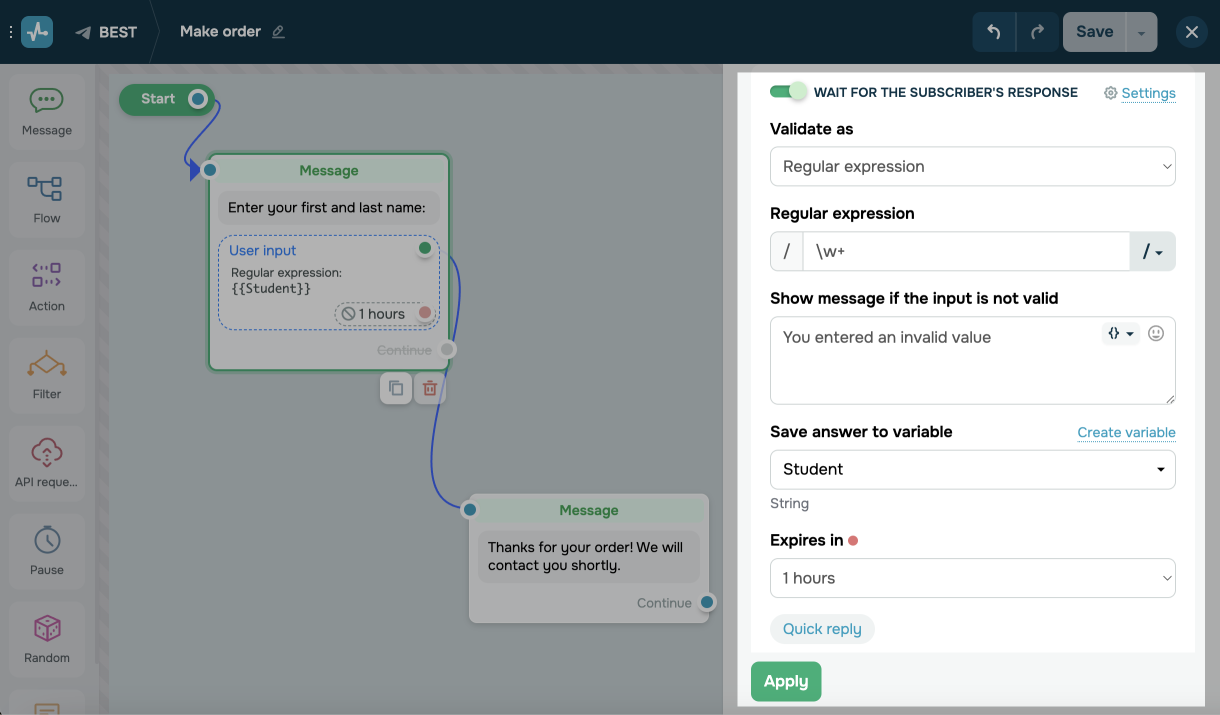
Enter your expression in the Regular Expression field. We will look at an example of an expression to check if you entered Yes and No with different cases.
You can check regular expression validity on the regex101 website. There, in the Regex Library section, you can find templates of commonly used expressions with explanations.
Enter the message to appear when one enters data incorrectly. You can use variables and emojis.
We recommend that you change the default error message and specify what you want to get in response with an example value to make it easier for the user to navigate your bot and provide the correct data.
Select the variable you want to save the answer to or create a new one by clicking Create Variable.
Don't forget to set a waiting period for the response to prevent the user from entering any values other than those you have requested for a period of time.
Note: when the Waiting for subscriber's response element is waiting for a response, triggering other flows by triggers and menu clicks does not work.
You can also use quick replies for the Regular expression validation type to help the users with predefined responses.
Click Apply.
How users interact with the bot using a regular expression
An example of using regular expressions to quantitatively check the introduction of a phrase from any two words /^[^\s]*\s[^\s]*$/
If a subscriber enters the wrong number of words, they will receive an incorrect input message. If the number of words is correct, the subscriber will receive a success message.
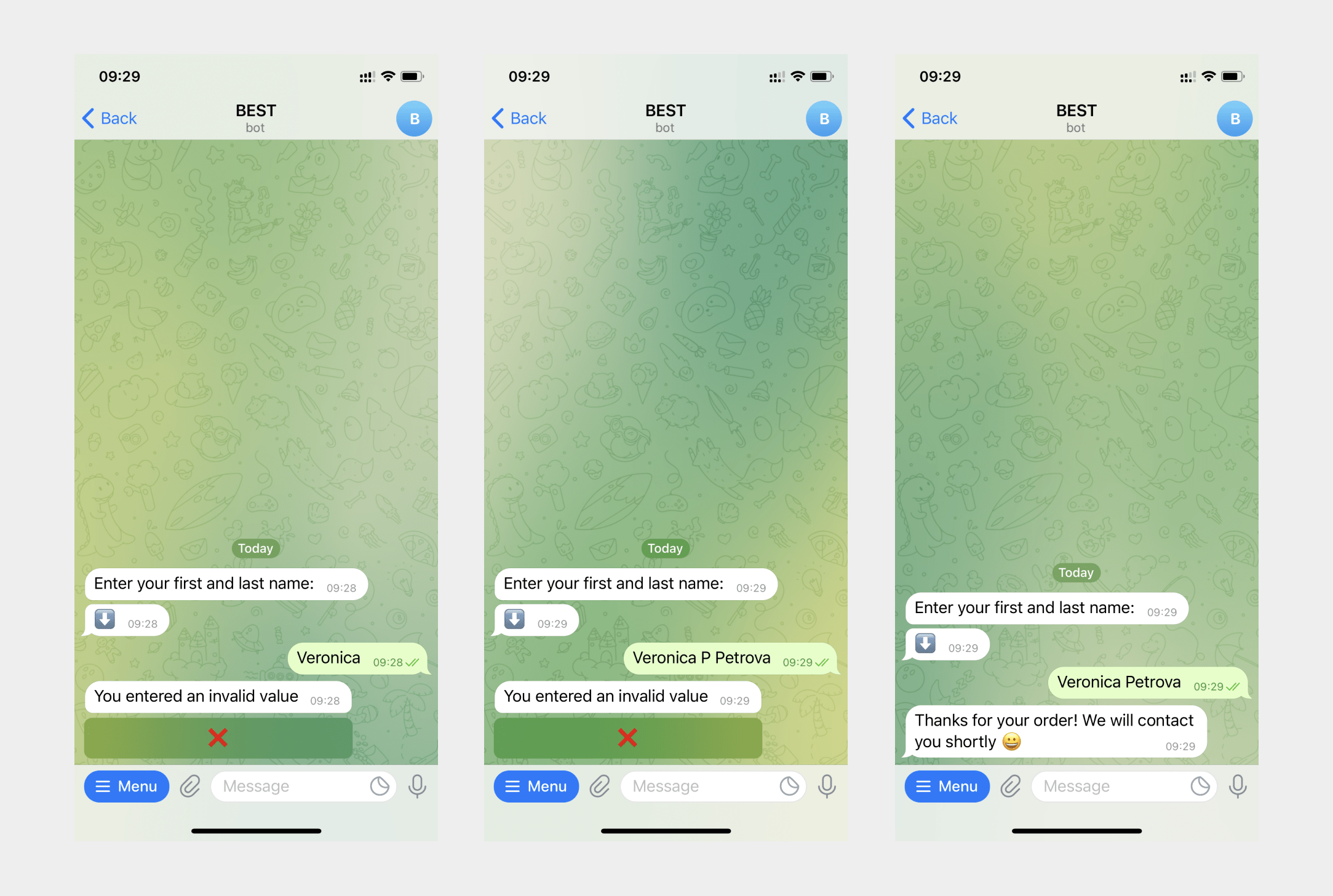
An example of using regular expressions for dichotomous questions with Yes and No statements.
In the Message element, we add a question, two buttons, and input user data with a regular expression ^(?:Yes|No|)$, where after ?: we enter values that we want to get and write to a variable, | - operator or, ^ and $ denote the beginning and end of the string. If the user does not click one of the buttons but enters their own text, that is not relevant to the expected answer, the message will remind you to enter or click one of the statements if the data is entered incorrectly.
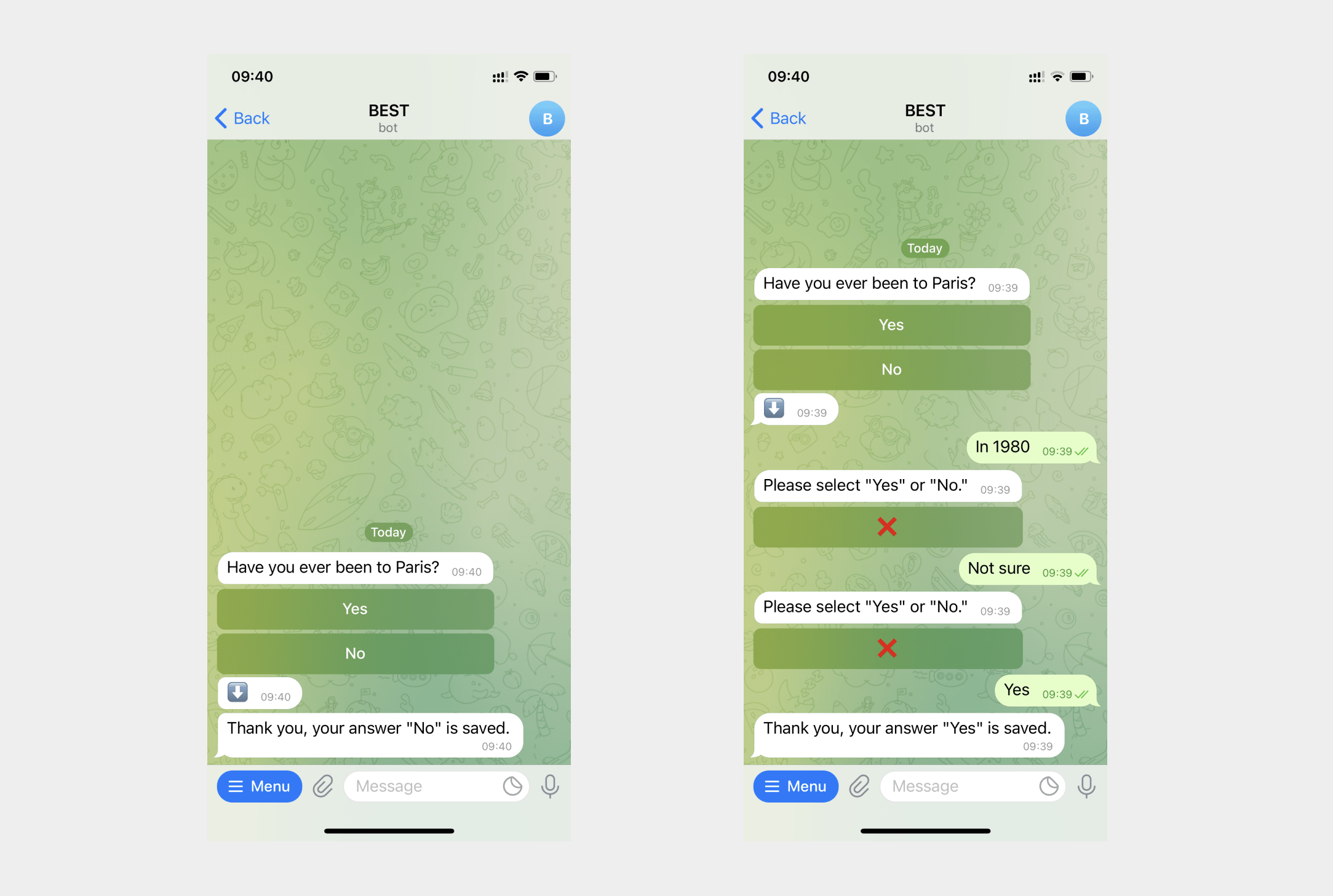
An example of using regular expressions to query for an email address at gmail.com.
In the Message element, add a question and user input with the regular expression (\w|^)[\w.\-]{0.25}@(gmail)\.com(\w|$) and correct the error message. See this message decoded below.
If a user enters an email on a domain other than gmail.com, the message will remind the user to enter an email on the gmail.com domain to access Google Docs, if the data is not entered correctly.
Note that data written using regular expressions is written to variables of the String type. You won't be able to send campaigns to them in the service. To collect contact data for sending messages, use the data entry type Email and Phone.
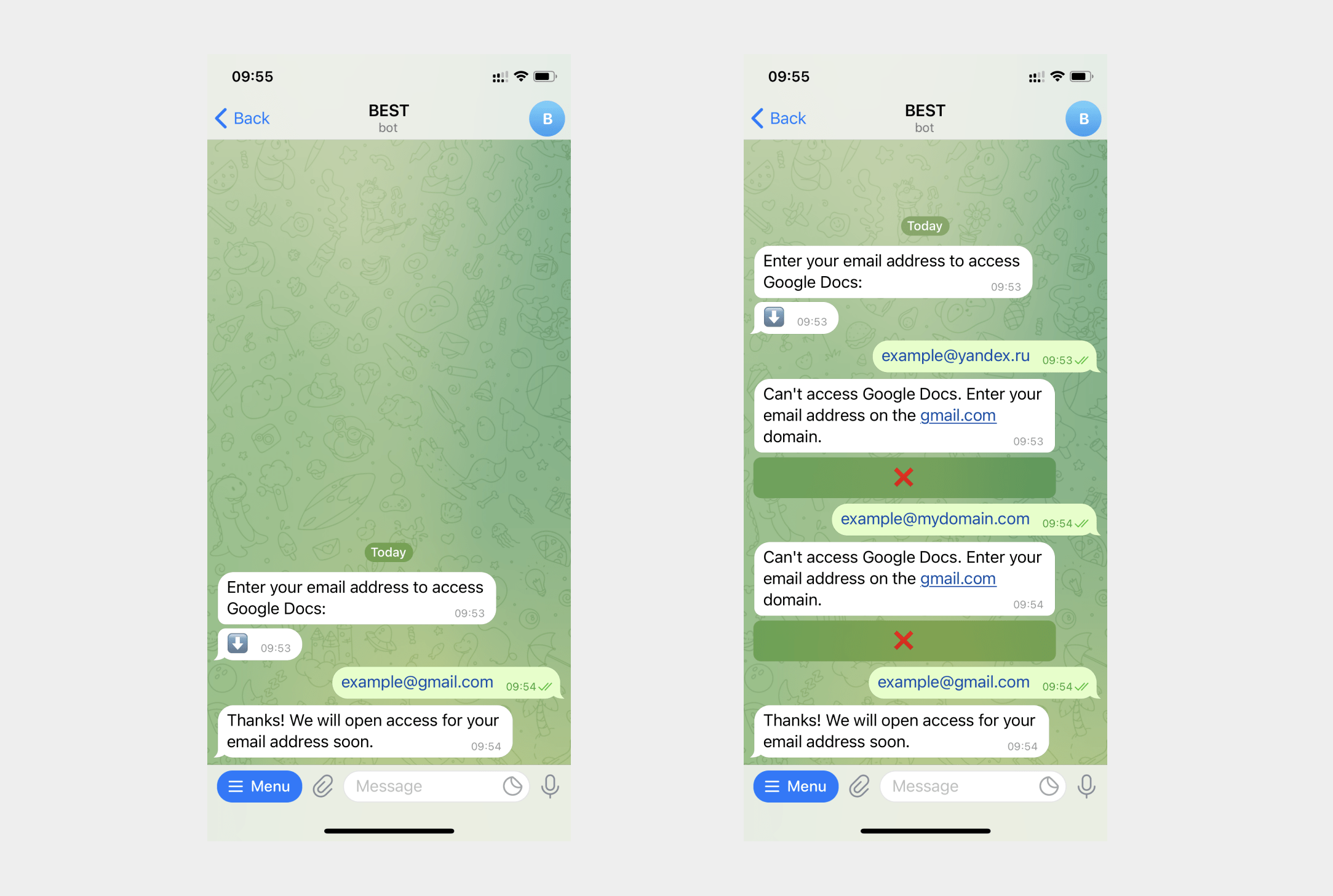
Responses with data from users are saved to chatbot audience variables. You can view saved responses in the Audience tab, use the variables in all subsequent text messages, and create mailings with segmentation.
Examples of regular expressions
To check a date in DD/MM/YYYY format:
/\d{1,2}\/\d{1,2}\/\d{4}/Explanation:
\d |
Waiting for any digits to be entered. |
{1,2} |
There may be one or two total digits ({1,2}). |
\. |
Shielding the . so that it appears as a normal period. |
To verify the date in the format DD.MM.YYYY:
/\d{1,2}\.\d{1,2}\.\d{4}/Explanation:
\d |
Waiting for any digits to be entered. |
{1,2} |
There must be one or two total digits ({1,2}). |
\. |
Shielding of the . so that it appears as a normal period. |
{4} |
There must be four total digits ({4}). |
To check for one word per line:
/^[^\s]*$/Explanation:
^ |
Start of line. |
[^\s] |
Any character, without a space after each character. |
* |
0 or more times. |
$ |
End of line. |
To check for two words in a line:
/^[^\s]*\s[^\s]*$/Explanation:
^ |
Start of line. |
[^\s] |
Any character to be entered, with no space after each character. |
* |
0 or more times. |
\s |
Space. |
[^\s] |
Any character, without a space after each character. |
* |
0 or more times. |
$ |
End of line. |
To check for three words in a line:
/^([^\s]*\s){2}[^\s]*$/Explanation:
^ |
Start of line. |
([^\s]*\s){2}) |
Are two words ({2}), each consisting of any character, without a space; after each character ([^\s]), which can be 0 or more times (*); each word ends with a space (\s). |
[^\s] |
Any character, without a space after each character. |
* |
0 or more times. |
$ |
End of line. |
To check for a specific word match: (e.g. Yes, yes, YES, or No, no, NO):
/^(?:Yes|Yes|YES|No|no|NO)$/Explanation:
^ |
Start of line. |
?: |
Waiting entry of words that match those entered. |
Да|да|ДА|Нет|нет|НЕТ |
Are the words yes, Yes, YES, no, No, NO to check for a match. |
$ |
End of line. |
Regular expression to check passport series and number (as two letters and six digits without space for old model or xxxxxxxx-xxxxxxx for new model):
/^([A-Z]{2}[0-9]{6})?$|[0-9]{8}[\s\-]?[0-9]{5}?$/Explanation:
^ |
Start of line. |
([A-Z]{2}[0-9]{6})? |
A string that can be repeated 0 or 1 times (?), which consists of two characters ({2}) between A and Z ([A-Z]) followed by six ({6}) digits of any value ([0-9]). |
$ |
End of line. |
| |
Operator or. |
[0-9]{8} |
Eight ({8}) digits of any value ([0-9]). |
[\s\-]? |
Space and dash ([\s\-]), which can be repeated 0 or 1 time. |
[0-9]{5} |
Five ({5}) any digits ([0-9]). |
$ |
End of line. |
To check a TIN (of 10 or 12 digits):
/^(([0-9]{12})|([0-9]{10}))?$/Explanation:
^ |
Start of line. |
[0-9]{12} |
Twelve ({12}) digits between 1 and 9 ([0-9]). |
| |
Operator or. |
[0-9]{10} |
Ten ({10}) digits ([0-9]). |
? |
Which can be repeated 0 or 1 time. |
$ |
End of line. |
To verify a bank card number in the format xxxx-xxxxxx-xxxx-xxxx:
/\d{4}[\s\-]?\d{4}[\s\-]?\d{4}[\s\-]?\d{4}/Explanation:
\d |
Waiting for any digits to be entered |
{4} |
of which there can only be four. |
[\s\-]? |
Space and dash, which can be repeated 0 or 1 time. |
To verify email addresses on domains (for example, to share documents in a Google account to a gmail.com address):
/(\w|^)[\w.\-]{0,25}@(gmail)\.com(\w|$)/Explanation:
(\w|^) |
First part of the capture, where \w - corresponds to any text character, ^ states the position at the beginning of the string. |
[\w.\-] |
Corresponds to one character from the list, where \w - corresponds to any text character, . corresponds to the character . and . matches - |
{0,25} |
of which there may be anywhere from 0 to 25. |
(gmail) |
Corresponds to the word gmail. |
\. |
Corresponds to the symbol . |
com |
Corresponds to the word com. |
(\w|$) |
Is the third capture group, where \w corresponds to any text character, | is the or operator, $ states the position at the end of the string. |
Last Updated: 27.12.2024
or